이론 공부 (딥러닝, 머신러닝, CNN, etc ..)
Deep Structured Learning, Deep Learning, 深層學習
여러 '비선형 변환기법'의 조합을 통해 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합.
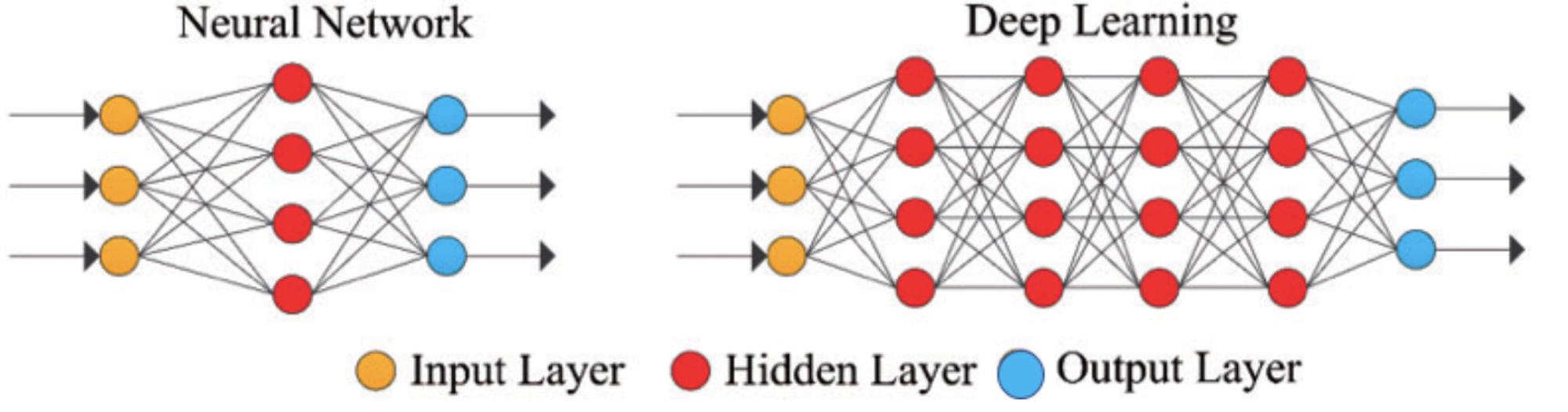
심층 신경망 (Deep Neural Network, DNN)
입력층(input layer)과 출력층(output layer) 사이에 여러 개의 은닉층(hidden layer)들로 이루어진 인공신경망(Artifical Neural Network, ANN)이다.
일반적인 인공신경망과 마찬가지로 복잡한 비선형 관계들을 모델링 할 수 있다.
심층 신경망은 비슷하게 수행된 인공 신경망에 비해 더 적은 수의 유닛(unit, node)들 만으로도 복잡한 데이터를 모델링할 수 있게 해준다.
머신러닝의 종류
supervised learning : 데이터에 정답이 있고, 이를 바탕으로 한 정답 예측 모델을 만듦
unsupervised learning : 데이터에 정답이 없고, 이를 컴퓨터가 알아서 분류하는 모델을 만듦
reinforcement learning : 컴퓨터에게 게임을 가르친다 생각하면 됨
weight : 가중치
bias : 편향


loss function(cost function) :
컴퓨터에서 w값의 오차를 최소화 한 값을 구함.
오차 값을 제곱하는 이유
실제 값에서 예측값을 뺐을 경우 음수값이 나올 수 있기 때문에(음수값이 나온다고 편차가 줄어드는 것이 아님) 절대값으로 제곱하여 더한 뒤 평균을 냄.
이렇게 해서 적용하고.. 어쩌고 하다 보면 Hidden layer의 여부 상관없이 유사한 결과가 나오게 됨.
이를 해결할 수 있는 방법 -> activation function (활성함수)

딥러닝 학습 과정
1. w값들을 랜덤으로 찍음
2. w값을 바탕으로 총손실 E를 계산함
3. 경사하강법을 이용하여 새로운 w값으로 업데이트
(총손실 E가 더 이상 줄어들지 않을 때까지 2, 3의 과정을 반복함)
learning rate : 가짜 최저점 말고 진짜 최저점을 찾기 위해 사용.
learning rate는 optimizer가 존재함 : 학습 중간 learning rate를 어떤 식으로 수정해야 학습을 더 빠르고, 효과적으로 진짜 최저점을 찾아주는 역할.
optimizer의 종류
- momentum: 가속도를 유지
- adagrad: 자주 변하는 w는 작게, 자주 변하면 크게
- rmsprop: adagrad인데 제곱함
- adadelta: adagrad인데 a가 너무 작아져서 학습 안 되는 거 방지해줌
- Adam: rmsprop + momentum
여러개 써보고 모델과 어울리는 거 선택하면 되지만 대부분 Adam을 사용함
모델 훈련의 목적
입력된 훈련 데이터의 손실을 최소화 하는 것.
모델 훈련 전 모델에 최적화된 하이퍼 파라미터들을 설정해주는 과정을 Compile이라고 함.
Compile에 포함되는 필수 요소
1. Optimizer : 네트워크 가중치 업데이트 결정하며 전체 훈련 과정 속도와 안정성을 결정
- 경사하강법( SGD), Adam, RMSprop, AdaGrad, AdaDelta 등이 많이 사용됨
2. loss : 손실 함수 (cost function or loss function)
- 이진 분류 문제 (binary classification problem) : binary-cross-entropy
- 다중 분류 문제 (multi-class classification problem) : categorical-cross-entropy
- 회귀 문제 (regression problem) : mean-squared-error
3. metrics : 훈련, 테스트 과정에서 활용되는 오차 평가 지표
- 평균제곱오차(MSE), 평균절대오차(MAE)
- 분류 문제에서는 정확도로 성능 평가 metrics = ['accuracy']
model.compile()을 통해 정립한 모델은 model.fit()으로 훈련시킨다.
(훈련시킬 때 훈련 데이터(features, target)와 batch_size, epoche를 정해줘야 한다)
1. epochs : 전체 데이터 셋이 학습하는 수 (forward/backward pass를 완료하는 수)
- 여러 epoch을 거치면서 모델 파라미터 값도 반복적으로 업데이트되어서 모델 성능이 향상됨
2. batch_size : 데이터 셋을 나누는 크기
- 훈련 데이터가 크면 ephoch 과정이 오래 걸리기 때문에 데이터를 나눠서 훈련함
모델 훈련이 완료되면 테스트 모델 예측 정확도를 측정해야 함.
Keras의 경우 - model.evaluate()를 이용하여 모델을 평가 : model.compile()에서 입력한 loss와 metrics값을 알려줌
CNN : Convolutional Neural Network
일반적인 Deep Neural Network에서 이미지나 영상과 같은 데이터를 처리할 때 발생하는 문제점들을 보완한 방법.
Convolutional 연산을 반복적으로 진행하면서 이미지의 특징을 검출함.

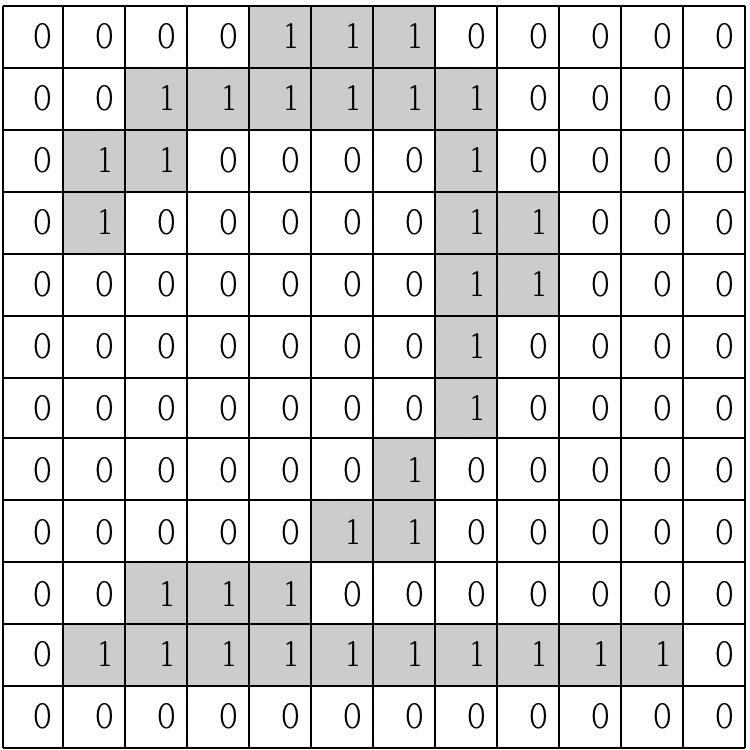
이미지의 경우 하나의 row로 표현되지 않기 때문에 DNN 방식으로 이미지를 학습 시킬 때의 문제점이 존재함.
이미지를 픽셀로 표현했을때, 회색이 들어있는 픽셀은 1이 들어있고, 흰색 픽셀의 경우 0이 들어있다고 가정.
CNN에서는 이 이미지의 한 픽셀과 주변 픽셀들의 연관관계를 유지시키며 학습시키는 것을 목표로 함(DNN보다 손실이 적음)
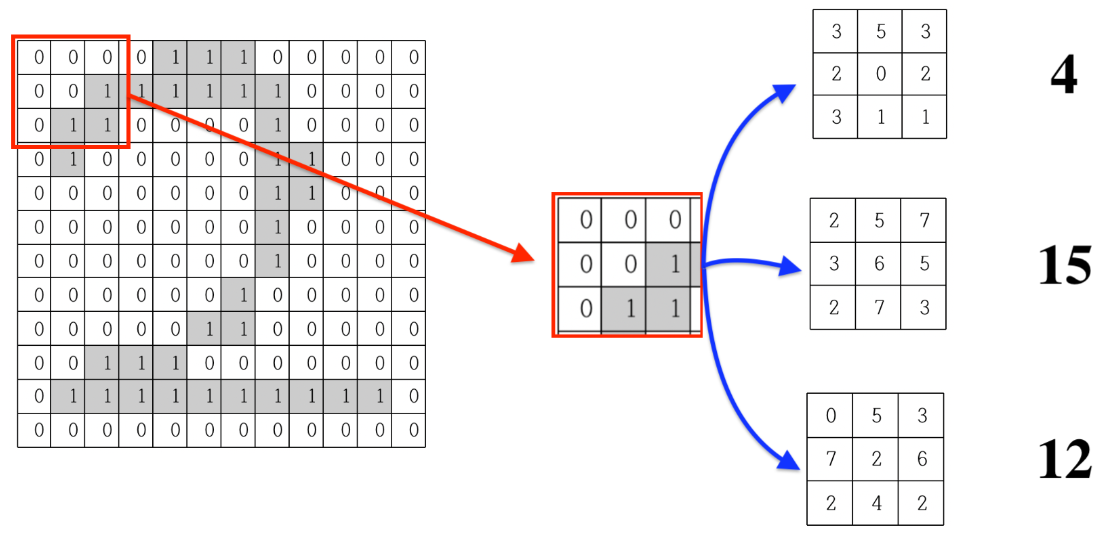
일단은 하나의 이미지로부터 픽셀 간의 연관성을 살린 여러 개의 이미지를 생성하는 것에서 시작 :
3x3 크기로 이미지를 뽑아내어 마찬가지로 3x3 크기의 랜덤값을 갖고 있는 데이터와 각 픽셀을 곱해서 더해줌.
이때, 랜덤값을 갖고 있는 3x3 데이터를 필터라고 함.
계산해보면 각 필터의 값에 따라 4, 15, 12와 같이 서로 다른 값이 발생한다는 것을 알 수 있음.
= 9개의 픽셀로부터 1개의 값이 생성되며, 한 칸씩 옮겨가며 생성하다 보면 12x12 이미지에서는 필터 하나가
10x10 크기의 이미지를 생성하게 됨
- 12x12 크기 이미지가 10x10으로 줄어드는것은 결국 손실이 아닌가?
이를 해결하기 위해 padding이라는 값을 주게 됨
padding : 원래 이미지의 양 옆에 0값을 갖는 데이터를 추가하여 위와 같은 방법을 통해 손실된 이미지를
padding을 통해 원래 크기와 동일한 이미지를 유지하도록 하는 방법.
이러한 과정을 CNN에서는 Convolution이라고 한다.
Convolution 과정을 통해 많은 이미지를 생성한 것은 좋은데, 이제는 너무 많아졌다는게 문제임..
하나의 이미지에서 Convolution 과정을 거칠 때마다 5배씩 이미지가 생성되게 됨.. 그래서 Pooling 사용.
Pooling : Convolution과 유사한 과정이긴 함. 이미지를 5배씩 뻥튀기시키는 Convolution과는 다르게,
1개의 이미지에 1개의 출력을 만들면서 동시에 기존 이미지에 Padding 없이 Filter만 적용하여 크기를 줄이는 방법을 말함.
Flatten : 다차원 배열을 1차원 벡터로 변환하는 역할을 함.
입력 이미지 or 다차원 데이터를 평평한 형태로 바꾸어 next layer인 완전 연결층(Fully Connected Layer)에 전달할 수 있도록 해줌.
= 하나의 이미지로부터 다양한 특이점들을 뽑아내어 1차원의 데이터로 변형하는 과정
(완전연결층은 입력 데이터를 펼쳐진 형태의 Vector로 받아들이고, 이를 사용하여 분류, 회귀 등의 작업을 수행)
(ex: 28x28 크기의 이미지를 1차원(28x28=784 크기) 벡터로 변환함)

Convolution과 Pooling을 반복해주면 이미지의 수는 많아지면서 크기는 점점 줄어들게 됨.
최종적으로 도출된 nxn 이미지는 특정 이미지에서 얻어논 하나의 특이점 데이터가 됨.
= 2차원이 아닌 1차원의 Row 데이터로 취급해도 무관한 상태가 됨.
Flatten 과정을 거치면 이후에는 DNN과 동일하게 만들어진 네트워크를 통해 Output을 출력하게 된다.
CNN의 layer들
Convolution layer : 특징을 추출함 (feature extraction)
Pooling layer : 특징을 추출함2 (feature extraction)
Fully-connected layer : 분류 (classification)
TenserFlow VS Keras
TenserFlow
구글에서 개발한 오픈소스 딥러닝 프레임워크, 다양한 수준의 유연성과 저수준 제어를 제공함
모델의 아키텍처 및 학습 과정을 세부적으로 제어할 수 있고, 사용자가 모델을 고도로 맞추거나 사용자 정의 가능
TenserFlow 2.x버전부터는 Keras가 표준 라이브러리로 포함되어 있음. 쉽게 사용가능한 고수준 API 제공
= 다양한 딥러닝 작업에 대한 저수준 제어를 제공하는 프레임워크
Keras
딥러닝 모델을 빠르고 간편하게 만들고 학습시키기 위한 고수준 딥러닝 라이브러리.
모델 구성, 학습 및 평가를 단순화한 API를 제공하여 빠른 프로토타이핑과 간단한 모델 작성을 지원함.
= TenserFlow보다 더 높은 수준의 추상화와 간결성을 제공하는 라이브러리.